Doppelgänger
Interactive code clone detection tool for identifying and eliminating duplicated Java code.
2 min read
What is it?
Doppelgänger is an interactive application I built together with my partner at university, to identify and help eliminate duplicated code in Java applications. It combines backend AST (Abstract Syntax Tree) analysis with visual exploration tools to make code clone detection both thorough and actionable.
The tool analyzes both local projects and those hosted on public Git repositories, providing an interactive interface to explore detected clones and work toward refactoring them.
GitHub: https://github.com/loehnertz/Doppelgaenger
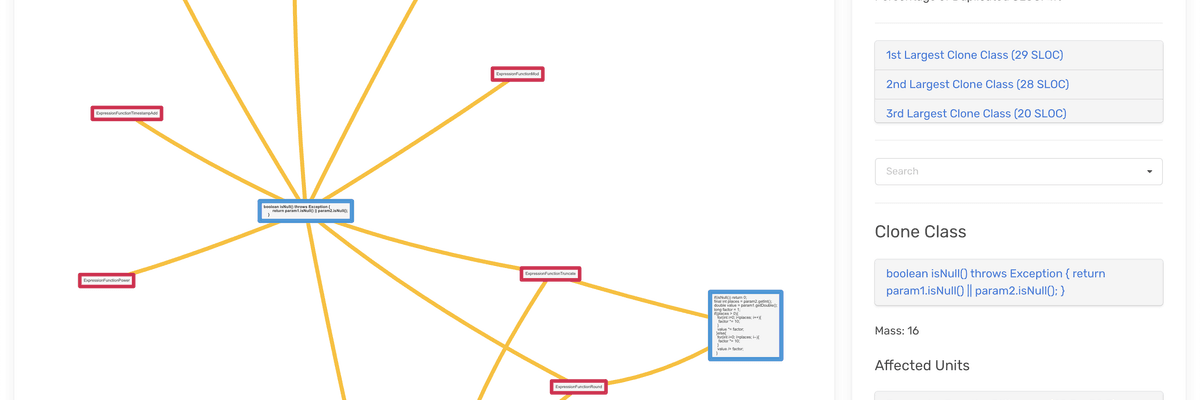
Clone detection types
Doppelgänger supports three levels of code clone detection: Type One: Exact Copies: Identical code ignoring only whitespace and comments. The “literally copy-pasted” clones.
Type Two: Syntactical Similarities: Structurally similar code allowing identifier variations (like different variable names). The “copy-pasted this and renamed some things” clones.
Type Three: Modified Copies: Code copies with modified, added, or removed statements. The “copy-pasted this and changed a few lines” clones.
You can configure similarity and thresholds to balance detection accuracy against analysis speed, which is important for large codebases where you don’t want to wait forever for results.
How it works
The backend uses AST parsing and hashing to identify code clones. This is more reliable than simple text comparison because it understands code structure rather than just matching strings.
The frontend then lets you visually explore the detected clones – see where they are, how similar they are, and which ones would have the biggest impact if refactored.
Key features:
- Detect duplicated source code across Java projects
- Analyze local projects or public Git repositories
- Advanced visualization interface for exploring clones
- Interactive refactoring workflow
- Configurable detection sensitivity
Tech stack
Backend:
- Kotlin using the Ktor web framework
- AST parsing (using JavaParser) and hashing for clone identification
- Configurable similarity algorithms
Frontend:
- Vue.js for the interactive visualization layer
- Real-time exploration of detected clones in graph vue (using vis.js)